AI embeddings are powerful. We’re working on Project Cyborg, a project to create a DevOps bot.
There’s a lot of steps to get there. Our bot should be able to analyze real-world systems and find our where we could implement best practices. It should be able to look at security systems and cloud deployments to help us better serve our customers.
To that end, our bot needs to know what best practices are. All of the documentation for Azure and AWS is available for free, and it’s searchable. However, online documentation doesn’t help with problem solving. It only helps if you have someone capable running a search. We want to be able to search based on our problems and real-world deployments. The solution: embeddings.
AI Embeddings
Here’s the technical definition: Text embeddings measure the relatedness of text strings.
Let’s talk application: embeddings allow us to compare the meaning of sentences. Instead of needing to know the right words for what you’re searching for, you can search more generally. Embedding enables that.
Embeddings work by converting text into a list of numbers. Then, those numbers can be compared to one another later, and similarities can be found that a human couldn’t detect. Converting text to embeddings is not terribly difficult. OpenAI offers an embedding model that runs off of Ada, their cheapest model. Ada has a problem, though.
Ada has a memory problem
Ada is a powerful model, and if it can keep track of what it’s supposed to be doing, it does excellent work. However, it has a low context length, which is just a fancy way saying it has Alzheimer’s. So, you can’t give Ada long document and have it remember all of it. It can only hold on to a few sentences in its memory at a time. More advanced models, like Davinci, have much better memory. We need a way to get Ada to remember more.
Langchain
We’ve been using langchain for a few different parts of Project Cyborg, and it has a great tool in place for embedding as well. It has tools to split documents up into shorter chunks, so that Ada can process them one at a time. It can then store these chunks together into a Document Store. This acts as long-term memory for Ada. You can embed large documents and collections of documents together, and then access them later.
By breaking it up documents into smaller pieces, it allows you to search your store for chunks that would be relevant. Let’s go over some examples.


Here you can see that we ask a question. An AI-model ingests our question, and then checks its long-term memory, our document store for the answer. If it knows the answer, it will reply with an answer and reference where it got that answer from.
Fine-Tuning vs. Embedding
Embeddings are different from fine-tuning in a few ways. Most relevant, embeddings are cheaper and easier to run, both for in-house models and for OpenAI models. Once you’ve saved you documents into a store, you can access them using few tokens and with off-the-shelf models. The downside comes in the initial embedding. To convert a lot of documents to an embedded format, like we needed to, takes millions of tokens. Even at low rates, that can add up.
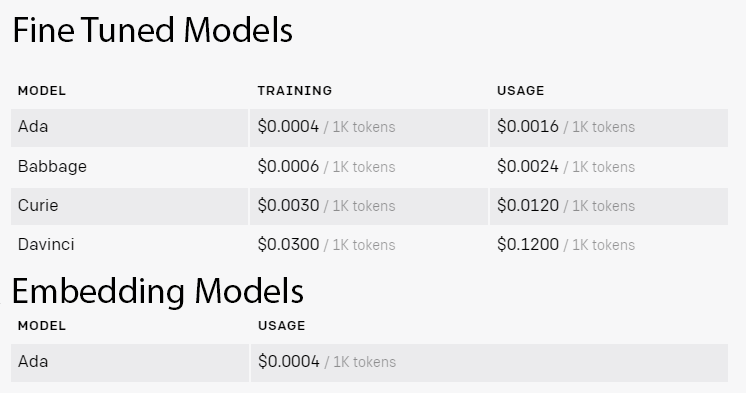
On the flip side, fine-tuning will typically use far fewer tokens than embedding, so even though the cost per token is much higher, it can be cheaper to fine-tune a model than to build out an embedded document store. However, running a fine-tuned model is expensive. If you use OpenAI, the cost per token is 4X the price of an off-the-shelf model. So, pick your poison. Some applications can take advantage of the higher initial cost, but then the cheaper cost of processing later.