Classification
We’re hard at work on Project Cyborg, our DevOps bot designed to enhance our team to provide 10x the DevOps services per person. Building a bot like this takes a lot of pieces working in concert. To that end, we need a step in our chain to classify requests: does a query need to go to our Containerization model or our Security model? The solution: classification. A model that can figure out what kind of prompt it has been given. Then, we can pass along the prompt to the correct model. To test out the options on OpenAI for classification, I trained a model to determine if news articles would be relevant to our business or not.
Google News
I started by pulling down the articles from Google News.
from GoogleNews import GoogleNews start_date = '01-01-2023' end_date = '02-02-2023' search_term = "Topic:Technology" googlenews=GoogleNews(start=start_date,end=end_date) googlenews.search(search_term) result=googlenews.result()
This way, I can pull down a list of Google News articles with a certain search term within a date range. Google News does not do a good job of staying on topic by itself.
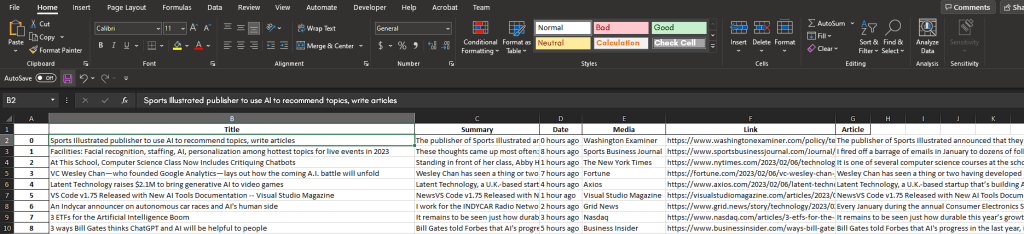
So, once I have this list of articles with full-text and summaries, I loaded them into a dataframe using Pandas and output that to an Excel sheet.
for i in range(2,20):
# Grab the page info for each article
googlenews.getpage(i)
result=googlenews.result()
# Create a Pandas Dataframe to store the article
df=pd.DataFrame(result)
Fine-Tuning for Classification
Then comes the human effort. I need to teach the bot what articles I consider relevant to our business. So, I took the Excel sheet and added another column, Relevancy.

I then manually ran down a lot of articles, looked at titles, summaries and sometimes the full text, and marked them as relevant or irrelevant.
Then, I took the information I have for each article, title, summary, and full-text, and combined them into one column. They form the prompt for the fine tuning. Then, the completion is taken from the relevancy column. I put these two columns into a csv file. This will be the training set for our fine-tuned model.
Once I had the dataset, it was time to train the model. I ran the csv through OpenAI’s data preparation tool.

I got out our training dataset and our validation dataset. With that in hand, it was time to train a model. I selected Ada, the least-advanced GPT-3 model available. It’s not close to ChatGPT, but it is good for simple things like classification. A few cents and half an hour later, I have a fine-tuned model.
Results
I can now integrate the fine-tuned model into my Google News scraping app. Now, it can pull down articles from a search term, and automatically determine if they are relevant or not. The relevant ones go into a spreadsheet to be viewed later. The app dynamically builds prompts that match the training data, and so I end up with a spreadsheet with only relevant articles.
